Regular expressions or “regexes” will enable us to examine patterns within our code. For example, we might want to validate that an email address is formatted correctly. Regular expressions will enable us to examine expressions in this fashion.
To begin, type code validate.py in the terminal window. Then, code as follows in the text editor:
`email = input("What's your email? ").strip()
if "@" in email: print("Valid") else: print("Invalid")`
Notice that strip will remove whitespace at the beginning or end of the input. Running this program, you will see that as long as an @ symbol is inputted, the program will regard the input as valid.
You can imagine, however, that one could input @@ alone and the input could be regarded as valid. We could regard an email address as having at least one @ and a . somewhere within it. Modify your code as follows:
`email = input("What's your email? ").strip()
if "@" in email and "." in email: print("Valid") else: print("Invalid")`
Notice that while this works as expected, our user could be adversarial, typing simply @. would result in the program returning valid.
We can improve the logic of our program as follows:
`email = input("What's your email? ").strip()
username, domain = email.split("@")
if username and "." in domain: print("Valid") else: print("Invalid")`
Notice how the strip method is used to determine if username exists and if . is inside the domain variable. Running this program, a standard email address typed in by you could be considered valid. Typing in malan@harvard alone, you’ll find that the program regards this input as invalid.
We can be even more precise, modifying our code as follows:
`email = input("What's your email? ").strip()
username, domain = email.split("@")
if username and domain.endswith(".edu"): print("Valid") else: print("Invalid")`
Notice how the endswith method will check to see if domain contains .edu. Still, however, a nefarious user could still break our code. For example, a user could type in [email protected] and it would be considered valid.
Indeed, we could keep iterating upon this code ourselves. However, it turns out that Python has an existing library called re that has a number of built-in functions that can validate user inputs against patterns.
One of the most versatile functions within the library re is search.
The search library follows the signature re.search(pattern, string, flags=0). Following this signature, we can modify our code as follows:
`import re
email = input("What's your email? ").strip()
if re.search("@", email): print("Valid") else: print("Invalid")`
Notice this does not increase the functionality of our program at all. In fact, it is somewhat a step back.
We can further our program’s functionality. However, we need to advance our vocabulary around validation. It turns out that in the world of regular expressions there are certain symbols that allow us to identify patterns. At this point, we have only been checking for specific pieces of text like @. It so happens that many special symbols can be passed to the compiler for the purpose of engaging in validation. A non-exhaustive list of those patterns is as follows:
`. any character except a new line
- 0 or more repetitions
- 1 or more repetitions ? 0 or 1 repetition {m} m repetitions {m,n} m-n repetitions`
Implementing this inside of our code, modify yours as follows:
`import re
email = input("What's your email? ").strip()
if re.search(".+@.+", email): print("Valid") else: print("Invalid")`
Notice that we don’t care what the username or domain is. What we care about is the pattern. .+ is used to determine if anything is to the left of the email address and if anything is to the right of the email address. Running your code, typing in malan@, you’ll notice that the input is regarded as invalid as we would hope.
Had we used a regular expression .*@.* in our code above, you can visualize this as follows:
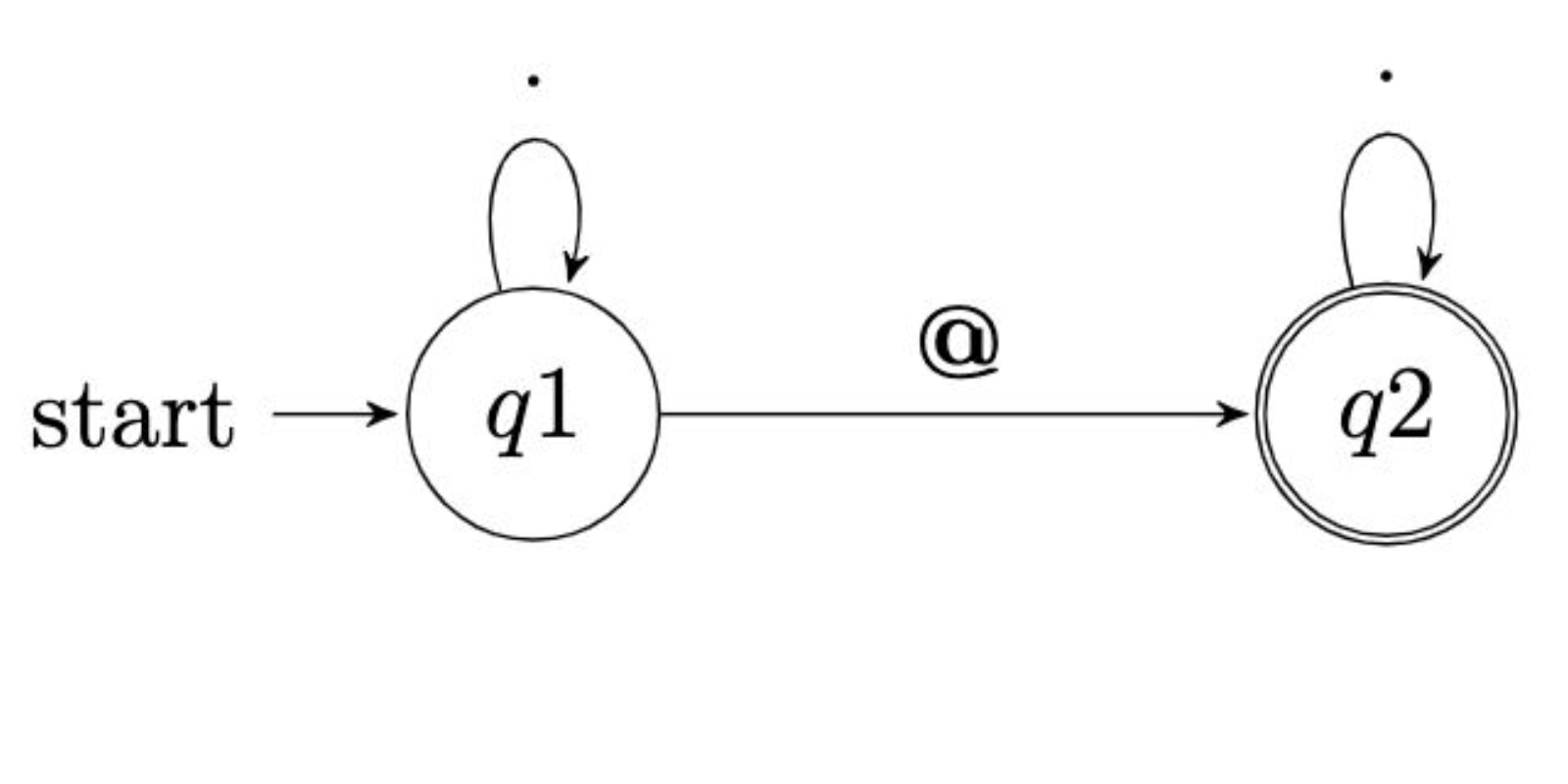
Notice the depiction of the state machine of our regular expression. On the left, the compiler begins evaluating the statement from left to right. Once we reach q1 or question 1, the compiler reads time and time again based on the expression handed to it. Then, the state is changed looking now at q2 or the second question being validated. Again, the arrow indicates how the expression will be evaluated time and time again based upon our programming. Then, as depicted by the double circle, the final state of state machine is reached.
Considering the regular expression we used in our code, .+@.+, you can visualize it as follows:
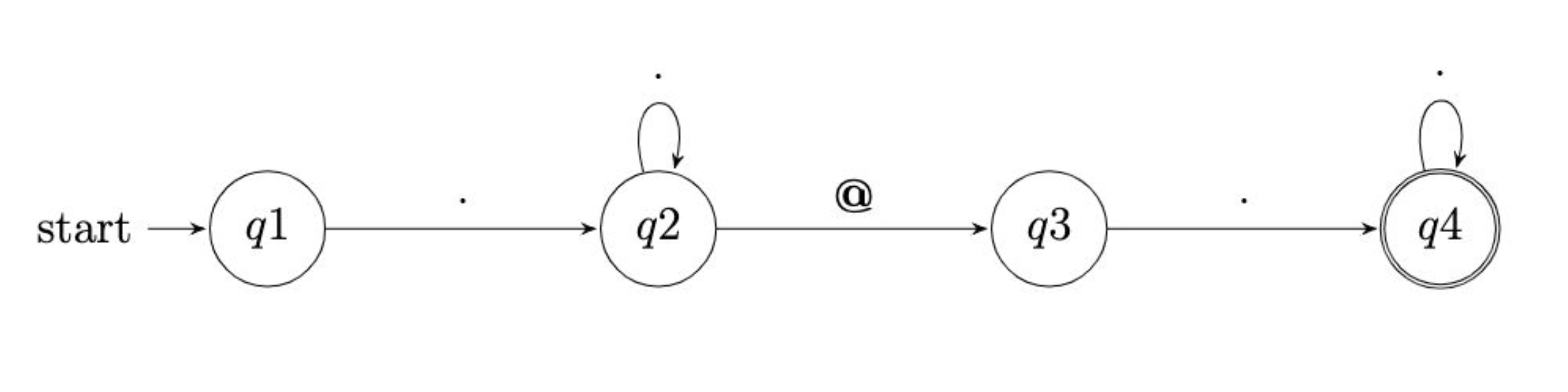
Notice how q1 is any character provided by the user, including ‘q2’ as 1 or more repetitions of characters. This is followed by the ‘@’ symbol. Then, q3 looks for any character provided by the user, including q4 as 1 or more repetitions of characters.